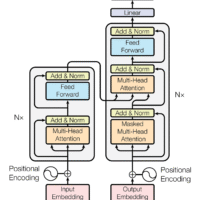
Large language models have a sneaky memory problem. When a model is generating text one token at a time, it keeps a running “cheat sheet” of everything it has already seen. This cheat sheet is called the KV cache (short for key-value cache). It stores tiny vectors for every single token in the conversation so far.
The longer the conversation or document gets, the bigger this cache grows. For big models with long contexts, it can eat up more memory than the model weights themselves. Slower responses, higher costs, and sometimes you just hit a hard hardware limit.
Google Research released TurboQuant earlier this year. It squeezes the KV cache down dramatically, to just 3 bits per number instead of the usual 16, while keeping answer quality exactly where it was. No retraining, no accuracy drop, and it even speeds things up on GPUs.
The best part? The paper shows that the first stage alone (called PolarQuant) is often all you need. It delivers most of the gains with almost no quality loss. Let’s focus right there.
The Easy Win: PolarQuant (Stage 1)
Each vector in the KV cache is a point in high-dimensional space, described by regular numbers along X, Y, Z… up to hundreds of dimensions (the standard Cartesian approach).
Traditional compression methods try to shrink those numbers directly, but they run into a problem: some numbers are huge outliers, others are tiny. Every small chunk of data needs its own “scale factor” stored at full precision. That extra bookkeeping eats up memory and slows things down.
PolarQuant takes a different angle (literally):
1. A quick random twist. It multiplies the vector by a shared random rotation matrix. This doesn’t change the math that matters (inner products and distances stay the same), but it makes the numbers behave in a predictable, well-behaved way.
2. Switch to polar coordinates. Instead of listing separate X, Y, Z values, it converts pairs of numbers into a radius (how far from the center) and an angle (the direction). Then it takes those radii and repeats the process, pairing them again into new radii and angles, until everything reduces to one final radius plus a bunch of angles.
Think of it like giving directions. The Cartesian way: “Go 3 blocks east, then 4 blocks north.” The polar way: “Go 5 blocks at a 37-degree angle.” Same destination, more compact description.
Why does this help so much?
After the random twist, the angles cluster tightly around predictable values with almost no wild outliers. That means you can use a fixed, pre-built grid to round the angles to low bit-widths (3 or 4 bits each) with no per-chunk scale factors and no extra bookkeeping.
PolarQuant alone cuts the KV cache to roughly 3.8 to 4.2 bits per original value. On long-context benchmarks like “needle in a haystack” at 100k+ tokens, or multi-document QA, quality is essentially unchanged. Google’s tests on Llama-3.1-8B, Gemma, and Mistral all show Stage 1 is already “nearly lossless” in their words. That’s why the paper calls it sufficient for most practical uses.
In short: PolarQuant turns messy high-dimensional data into a tidy angle-based code that’s compact to store and fast to compute. Like zipping a file in a way the computer can still instantly read.
A Bit More Detail on How It Actually Works
For those who want to peek under the hood, here’s the step-by-step:
Random preconditioning. A fixed random matrix (generated once and shared everywhere) rotates the vector. Fast to apply, and it ensures the numbers approximate a nice bell-curve distribution.
Recursive polar transform. Assuming a power-of-2 vector length (common in practice), pair every two numbers and turn them into one radius and one angle. Then pair the radii again into more radii and angles. Repeat log₂(d) times until you’re left with one radius (kept lightly quantized) and a sequence of angles.
Quantize the angles only. Because the angles are now independent and tightly concentrated, a simple uniform 1D quantizer works perfectly. No dynamic scaling needed.
Reconstruction. When the model needs the vector back for attention, it reverses the process using basic trig. Very fast on GPUs.
The paper proves this gives near-optimal compression for what matters most in attention (preserving similarity scores). And because it runs token-by-token as the model generates, there’s zero calibration data or setup time required.
Early discussion is already showing up in the llama.cpp community, and the reaction is pretty much “it just works.”
Why This Matters
Longer contexts are where AI is heading. Analyzing full books, long videos, extended conversations. Without compression like this, you either need enormous GPUs or you start making quality trade-offs. PolarQuant’s first stage makes high-quality long-context inference practical on hardware that most people actually have access to.
TurboQuant adds a second stage for an extra refinement step, but for most real-world KV cache use cases, Stage 1 is the part worth paying attention to.
Give it a look if you’re working anywhere near inference optimization. The results are hard to argue with.
References: Google Research Blog (March 2026): “TurboQuant: Redefining AI Efficiency with Extreme Compression” PolarQuant: arXiv:2502.02617 TurboQuant: arXiv:2504.19874