Introduction
What happens when you train a character-level GPT model on the entire works of William Shakespeare? You get something gloriously chaotic, amusingly nonsensical, and perhaps the worst Shakespeare ever written. In this post, I’ll walk you through the process of building and training my own GPT model on Shakespeare’s corpus, share some of the “unique” results, and take a closer look at why the output ended up being… well, as tragic as it is comedic. Spoiler: Shakespeare himself would likely weep in disbelief.
The Vision
I’ve always been fascinated by language models, and what better way to explore their potential than by feeding them the literary goldmine that is Shakespeare’s complete works? From Hamlet to Macbeth, I wanted to see if my model could learn the rhythms, the language, and the dramatic flair that made Shakespeare an icon. But instead of elegant soliloquies and moving scenes, the results turned out to be something much closer to the ravings of an Elizabethan madman.
The Training Process
Training this model was no small feat. It took about 24 hours to train on a Mac mini M1 with 8gb RAM, and during this time, the computer was essentially unusable. Despite the challenges, it was fascinating to see how the model evolved over time.
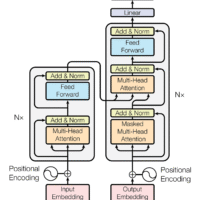
I used a model architecture inspired by the Transformer model introduced in the 2017 ‘Attention is All You Need’ paper. Specifically, I employed a multi-head attention mechanism, feed-forward neural networks, and layer normalization—all organized into a series of blocks that process the input sequence iteratively.
The model architecture included several key components:
- Multi-Head Attention Mechanism: Implemented via the
multiHeadAttentionclass, this allows the model to attend to different parts of the sequence simultaneously, enhancing its ability to understand relationships between characters. In the code, the attention mechanism is designed to allow tokens to communicate with each other. To prevent “future communication,” we use a lower triangular matrix, attention mask—ensuring that each token only attends to those on its left, effectively preventing the model from cheating by looking ahead.
class multiHeadAttention(torch.nn.Module):
def __init__(self, n_heads, head_size):
super().__init__()
self.heads = torch.nn.ModuleList([Head(head_size) for _ in range(n_heads)])
self.proj = torch.nn.Linear(n_embd, n_embd)
self.dropout = torch.nn.Dropout(dropout)
def forward(self, x):
B, T, C = x.shape
# apply all the heads
y = torch.cat([h(x) for h in self.heads], dim=-1)
y = self.dropout(self.proj(y))
return y
class Head(torch.nn.Module):
''' single attention head'''
def __init__(self, head_size):
super().__init__()
self.key = torch.nn.Linear(n_embd, head_size, bias=False)
self.query = torch.nn.Linear(n_embd, head_size, bias=False)
self.value = torch.nn.Linear(n_embd, head_size, bias=False)
self.register_buffer('mask', torch.tril(torch.ones(block_size, block_size)))
self.dropout = torch.nn.Dropout(dropout)
def forward(self, x):
B, T, C = x.shape
k = self.key(x) # (B T C)
q = self.query(x) # (B T C)
v = self.value(x) # (B T C)
weights = q @ k.transpose(-1, -2) * C**-0.5 # (B T T)
weights = weights.masked_fill(self.mask[:T, :T] == 0, float('-inf'))
weights = torch.nn.functional.softmax(weights, dim=-1)
weights = self.dropout(weights)
y = weights @ v # (B T C)
return y- Feed-Forward Neural Networks (FFN): These are simple two-layer networks with ReLU activation, adding non-linearity and helping the model to capture complex patterns in the text. After the tokens communicate using the attention mechanism, the FFN component performs computation on those communications, allowing the model to refine and transform the information gathered.
class FFN(torch.nn.Module):
# RELU non linearity
def __init__(self, n_embd):
super().__init__()
self.net = torch.nn.Sequential(
torch.nn.Linear(n_embd, 4 * n_embd),
torch.nn.ReLU(),
torch.nn.Linear(4 * n_embd, n_embd),
torch.nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)- Layer Normalization and Residual Connections: Used to stabilize the training and allow for effective gradient flow through the network. Each
Blockincludes these components to improve learning stability.
class Block(torch.nn.Module):
def __init__(self, n_embd, n_heads):
super().__init__()
self.multiHeadAttention = multiHeadAttention(n_heads, n_embd // n_heads)
self.FFN = FFN(n_embd)
self.norm1 = torch.nn.LayerNorm(n_embd)
self.norm2 = torch.nn.LayerNorm(n_embd)
def forward(self, x):
x = x + self.multiHeadAttention(self.norm1(x))
x = x + self.FFN(self.norm2(x))
return x- Positional Embeddings: These embeddings help the model recognize the order of the input sequence, crucial for generating coherent and structured text.
The complete implementation can be found here 👉 code.
The model was trained on the Shakespeare dataset, which had a total length of 1,115,394 characters with 65 unique characters. Here are some of the training results:
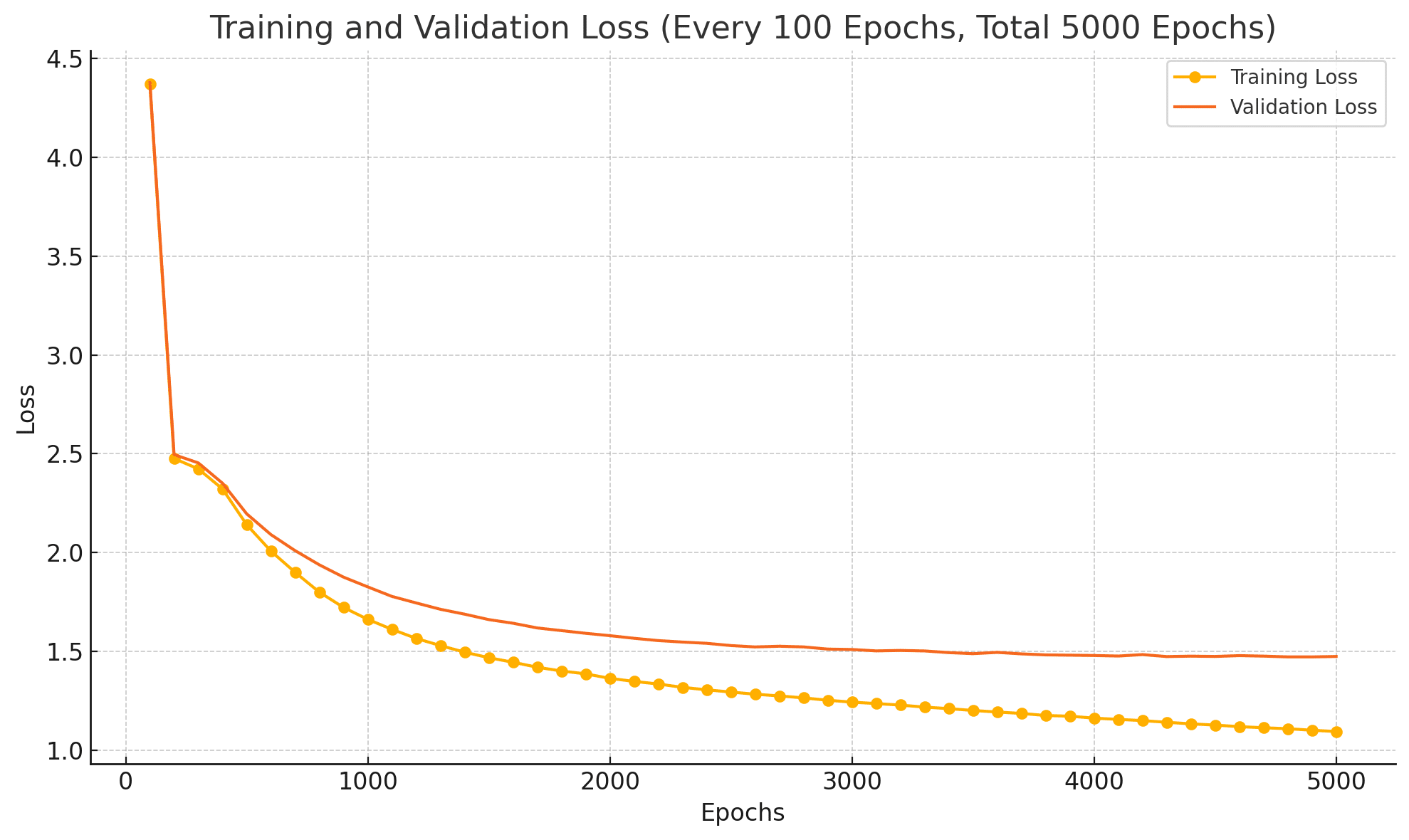
Over time, the model learned certain quirks of Shakespearean language—thees, thous, haths, and even a fondness for unusual punctuation. But while it managed to pick up some of Shakespeare’s vocabulary, it also generated texts that made little sense, both syntactically and narratively.
The Results: A Comic Masterpiece?
Let me share a snippet of the model’s “masterpiece”:
“…O horse! these servants is none put one of the reapons may be yours…”
“BRUTUS: ‘Tis so, title all that mock insignor.’ Provolat! O, nobled is battled functor! Lever son! Devonse, fly, thou shouldst do fett, uncounce’t.”
If you’re wondering whether these words have any meaning, the answer is… probably not. The output is a mixture of recognizable Shakespearean elements and absolute nonsense. Characters appear, seemingly without purpose, delivering lines that veer wildly from cryptic to comical. Autolycus exclaims something about a “noble sworn,” while Volumnia asks, “Tybalty; quite Cupitol!” —a strange echo of the Capitol, perhaps, or simply a glitch in the matrix.
The randomness is a direct result of the model being character-level. Without understanding context, it often produces phrases that sound vaguely Shakespearean but lack meaning or coherence. In other words, it’s Shakespeare, but without the brilliance. It’s a testament to just how much linguistic mastery Shakespeare had—the kind that can’t easily be replicated by statistical patterns alone.
Why Character-Level GPT?
You might ask: why use a character-level model at all, when more sophisticated token-level models exist? The answer is curiosity. Character-level models have an intrinsic charm—they build language from the ground up, grappling with every letter, punctuation mark, and space. There’s something fascinating about watching a model try to learn not just words, but spelling, phrasing, and punctuation all at once. It also presents a unique opportunity to explore the limits of language generation—to see how much (or how little) a model can capture when it doesn’t know what a word is.
Lessons Learned
The training process was not without its challenges. Character-level models have their charm, but they also bring unique difficulties. The multiHeadAttention, FFN, and other classes played a key role in trying to extract meaningful sequences from the dataset. However, the character-level approach often led to outputs that lacked overall coherence and structure.
- Attention Mechanisms: The attention heads worked well for focusing on different parts of the character sequence, but without the semantic awareness of words, the model had a hard time producing anything with real intent.
- Layer Normalization and Residual Connections: These components were essential in helping the model converge, though they could not compensate for the inherent difficulties of a character-level prediction task.
Despite these challenges, the model’s outputs are undeniably entertaining, and they remind us how hard it is to replicate true creativity. Shakespeare, after all, wasn’t just combining letters; he was creating worlds, conveying emotions, and capturing the human experience. My model, on the other hand, gave us this:
“Sweet your son, and selven; for then you they grant icture scorn fetch and us all.”
Make of that what you will.
Conclusion
Training a GPT model on Shakespeare was an experiment in the bizarre. The result was the “worst Shakespeare ever written”—a nonsensical, entertaining jumble of words that serves as a reminder of both the power and the limitations of machine learning. As AI continues to advance, perhaps one day we’ll see a model that can truly capture Shakespeare’s genius. Until then, I’ll be content with my model’s strange and wonderful ramblings.
Have you tried training your own language model on a unique dataset? I’d love to hear about your experiences in the comments below—especially if your results were as wonderfully awful as mine!