
What is a Transformer model?
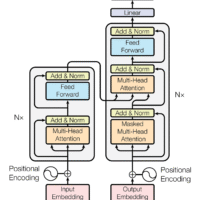
Transformer models are a type of neural network architecture introduced in the paper “Attention is All You Need” by Vaswani et al. in 2017. Unlike other neural network architectures, such as recurrent neural networks (RNNs) or convolutional neural networks (CNNs), which process sequential data using a fixed-size window, transformers use self-attention mechanisms to process entire sequences of input data in one go. This allows them to capture long-range dependencies and relationships between elements in a sequence more effectively.
Now what is self-attention, and why is it so special?
The attention mechanism in transformers allows the model to focus more on important parts of a sentence and less on irrelevant parts while processing language. This means the model can understand the meaning of words in the context of the sentence and make better predictions. The Transformer model assigns weights to each word in a sentence to determine its importance for understanding the overall meaning. These weights are calculated using an attention matrix, which helps the model identify which words are more significant than others.
How GPT Uses Transformers
GPT (Generative Pre-trained Transformer) models—developed by OpenAI—are built entirely upon the Transformer architecture. Instead of processing text from both directions like BERT, GPT models process text in one direction (left to right). This design makes GPTs especially good at generating coherent and contextually relevant text.
The “pre-trained” part means GPTs are trained on massive amounts of internet text to learn grammar, facts about the world, and various writing styles. After pre-training, they can be fine-tuned or prompted to perform specific tasks—like answering questions, writing code, or summarizing text.
Why Transformers Changed Everything
Before transformers, models struggled to handle long-term dependencies in language. RNNs and LSTMs could forget earlier words in long sentences, but transformers overcame this by using positional encodings and multi-head attention—allowing them to understand both global and local context simultaneously.
This innovation led to a revolution in AI:
- Better language understanding and generation (ChatGPT, Claude, Gemini)
- Improved machine translation
- Advances in computer vision (Vision Transformers)
- Multi-modal AI (models that process text, images, and audio together)
The Future of Transformers
Transformers continue to evolve with new architectures and optimizations. Models like GPT-4, Claude 3, and Mistral are more efficient, more aligned with human intent, and capable of reasoning across multiple domains. Researchers are also exploring smaller, faster transformers for edge devices and long-context models that can process entire books or videos at once.
Final Thoughts
Transformer models—and GPT in particular—represent one of the most significant leaps in AI history. By replacing recurrence with attention, they unlocked scalable learning across language, code, and even art. As the technology matures, we’ll see even more intelligent, creative, and personalized AI applications in everyday life.