DeepSeek-OCR: a paradigm shift in context compression
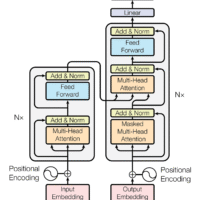
DeepSeek-OCR, unveiled on the 21 October 2025, introduces a visual -based method for compressing long text contexts (technode.com). Instead of representing every word as a separate token, the system maps pages of text into images and recovers the text via a vision–language model. This approach achieves 96–97% OCR precision when compressing at 9–10× ratios and maintains about 60% accuracy even at 20× compression (deepseek.ai). According to the DeepSeek team, a single A100‑40 GB GPU can process more than 200 000 pages per day using this method, and a cluster of 20 nodes can reach 33 million pages per day (deepseek.ai). By surpassing mainstream OCR models with far fewer vision tokens (technode.com), DeepSeek-OCR demonstrates that a picture can indeed be worth a thousand words.
From pattern completion to visual thought
In his recent podcast, Andrej Karpathy suggested that current language models are essentially pattern completers trained on random internet text and that a better way to build intelligent systems might involve pretraining on trillions of chain‑of‑thought examples. The idea is to create a separate “thinking model” that reasons step‑by‑step and then aligns it with a production model. The visual compression techniques pioneered by DeepSeek could catalyse this trajectory. By converting long contexts into compact vision tokens, an LLM can free up attention to reason through step‑wise thoughts rather than memorising raw text. Going further the potential to rendering all input as images before feeding it into an LLM could fundamentally change how these systems think and reason (venturebeat.com). If that is the case, then generating and consuming chain‑of‑thought data in visual form could become a natural extension of LLM training.
Rethinking AI memory
One of the central constraints on today’s language models is the context window: they can only “remember” a limited number of tokens at a time. Because DeepSeek-OCR compresses text up to 10× through optical mapping, it offers a practical path to expanding context windows by an order of magnitude. (venturebeat.com) reports that this could enable models with context windows reaching tens of millions of tokens. The research paper even hints at using multi‑resolution images as a form of computational forgetting: older conversation rounds could be downsampled to lower resolutions, consuming fewer tokens while preserving essential information. This resembles human memory, where details fade but salient patterns remain. Such a mechanism could give LLMs more persistent yet efficient recall, blurring the line between memory and perception.
Visual thinking and chain of thought
Humans rarely think in pure text. We sketch diagrams, draw mind maps and imagine spatial relationships. By giving models a perceptual interface through vision tokens, DeepSeek-OCR could allow them to “see” their own reasoning. A reasoning‑first model trained on chains of thought could generate diagrams or spatial representations of its logic, feed them back through an OCR‑style visual pipeline, and refine its understanding. This would create a virtuous loop between linguistic reasoning and visual intuition. Models might develop metacognitive skills like self‑verification and reflection, capabilities already explored in DeepSeek-R1 and similar reasoning models.
Implications for the future
The convergence of chain‑of‑thought pretraining and visual context compression points to a future where AI systems don’t just mimic human language but adopt aspects of human cognition. They could maintain larger memories, perform more deliberate reasoning and use visual representations to organise and recall information. As DeepSeek‑OCR shows, efficient visual encoding can reduce resource costs and improve scalability (deepseek.ai). The next frontier may involve training models to think both verbally and visually, unlocking new forms of creativity and problem‑solving.