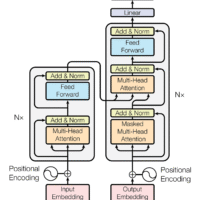
Traditional RAG pipelines assume documents are text. For a large class of real-world documents like financial reports, research papers, slide decks, and engineering specifications, this assumption discards much of the information that matters. We built a production document retrieval system that skips text extraction entirely and instead uses ColPali [1], a vision-language model, to embed document pages directly as images. This post walks through the architecture, the retrieval pipeline, and how we integrated Light-ColPali [4] token merging to reduce storage costs by 9x while retaining ~98% of retrieval quality.
None of the core techniques here are novel. ColPali was introduced by Faysse et al. [1], Light-ColPali by Jha et al. [4], and the underlying ColBERT late-interaction paradigm by Khattab and Zaharia [2]. What we describe is a practical, production-oriented implementation that composes these existing ideas into a deployable system and addresses the engineering concerns around job coordination, failure recovery, and storage scaling that arise when moving from research prototypes to running infrastructure.
Why Text Extraction Is Lossy
The standard RAG pipeline follows a well-established pattern: parse a PDF, extract text, chunk it into segments, embed each chunk as a dense vector, and index for nearest-neighbor retrieval. At query time, embed the question, retrieve the nearest chunks, and pass them to an LLM for answer generation. Lewis et al. [5] introduced this paradigm, and subsequent work has refined every stage with better chunking strategies, stronger embedding models like E5 [6], and dedicated vector databases.
The pipeline works well when documents are predominantly textual. But a significant fraction of real-world documents encode critical information in visual structures like tables, charts, diagrams, multi-column layouts, and annotated figures. Text extraction handles these poorly. OCR introduces transcription errors. Table parsers fail on irregular layouts. Charts produce no extractable text at all. Spatial relationships like a footnote tied to a figure or a header governing a table column are destroyed entirely.
The fundamental issue is that text extraction is a lossy transformation. The output of a PDF parser is a strict information subset of the rendered page. Any retrieval system built on that output inherits the loss.
ColPali: Embedding Documents as Images
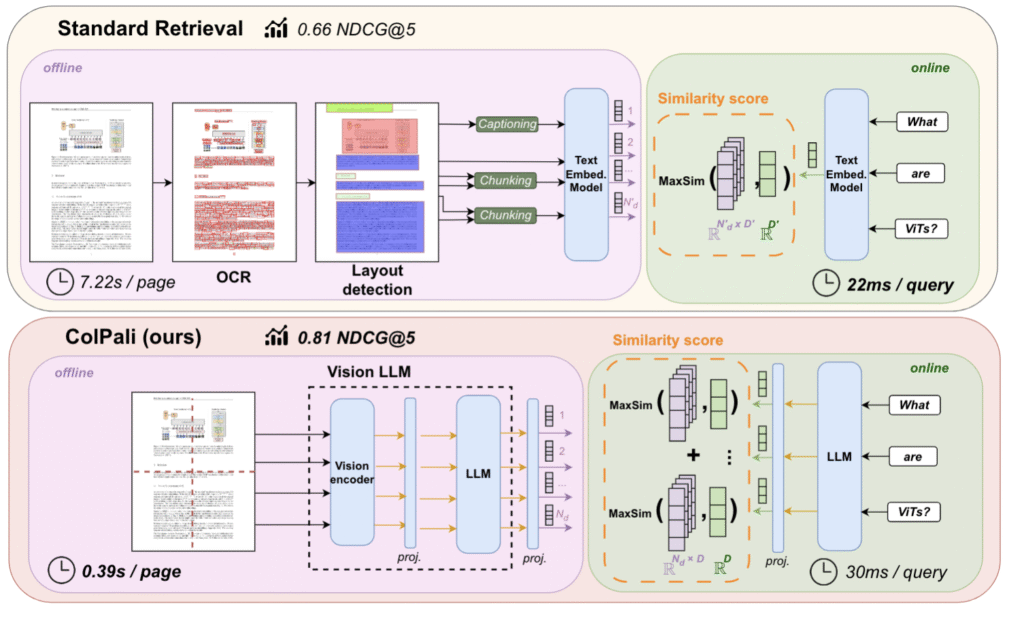
ColPali [1] takes a different approach entirely. Built on the ColBERT late-interaction framework [2] and using the Qwen2-VL vision encoder [3], ColPali accepts a document page as an image and produces embeddings directly from the visual content.
The key distinction from single-vector document embeddings is that ColPali generates patch-level embeddings. The model’s vision encoder decomposes each page image into a spatial grid of patches (small regions of the page) and produces an independent 128-dimensional embedding for each one. A typical page yields around 400 patches. Each patch captures the semantic content of its region: text, charts, table cells, whitespace, diagrams, all of it in spatial context.
For a page image I, ColPali produces a set of patch embeddings:
\mathbf{E}_I = \{(\mathbf{e}_i, \mathbf{b}_i)\}_{i=1}^{N_p} \newline
\ \\
where\ \mathbf{e_i} ∈ ℝ^{128}\ is\ the\ embedding\ and\ \bold{b}_i = (x₁, y₁, x₂, y₂) \in [0, 1]^4\ \newline is\ the\ normalized\ \text{bounding box for patch}\ \bold{i}\ on\ the\ page.This means each embedding is spatially grounded, so we know exactly where on the page its information came from.
This is what makes vision RAG fundamentally different from text RAG. Layout is preserved by construction. A table header stays associated with its column. A chart is embedded as a chart, not as garbled OCR output. The model sees the page the way a human reader does.
The tradeoff is storage: 400 embeddings per page is a lot of vectors.
System Architecture
Our system has three components: a FastAPI query API, one or more ingestion workers, and PostgreSQL with the pgvector extension. Source PDFs live in S3.
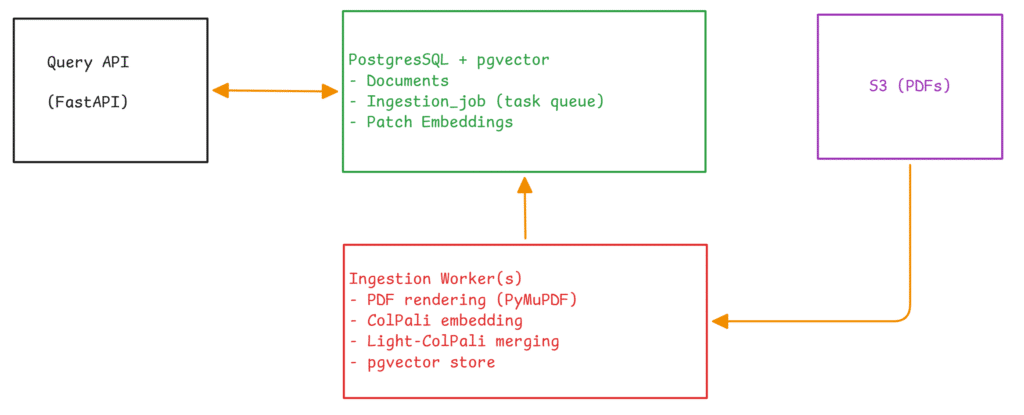
We use PostgreSQL for everything: document metadata, the job queue, and the vector embeddings. This is a deliberate choice. Dedicated vector databases like Pinecone or Qdrant offer specialized features, but a unified PostgreSQL deployment gives us ACID guarantees across job state and embedding storage, one fewer service to operate, and atomic operations like replacing all embeddings for a document in a single transaction. pgvector’s HNSW index handles approximate nearest-neighbor search on VECTOR(128) columns with cosine distance.
Ingestion: From PDF to Patch Embeddings
Job Coordination
Ingestion is asynchronous. An HTTP request creates a document record and enqueues a job. The job queue is a PostgreSQL table with lease-based coordination, no Redis or RabbitMQ required.
A worker claims jobs atomically using SELECT ... FOR UPDATE SKIP LOCKED, sets status = 'leased' with a time-limited lease (default 120 seconds), and begins processing. For long documents, the lease is renewed every 5 pages to prevent expiration during processing.
Failed jobs are retried with exponential backoff:
\delta(a) = \min\left(\delta_{\text{base}} \cdot 2^{\max(0,\, a-1)},\; \delta_{\text{max}}\right)where a is the attempt count, δ_base = 5s, and δ_max = 300s. After 5 failed attempts, the job moves to a dead letter state for manual inspection.
For idempotency, we record each document’s S3 ETag. On re-ingestion, if the ETag is unchanged and embeddings already exist for the current model version, the worker skips reprocessing entirely. A force flag bypasses this check.
Rendering and Embedding
The worker fetches the PDF from S3, renders each page as a PNG using PyMuPDF at 200 DPI (configurable), and feeds each image through ColPali (vidore/colqwen2-v1.0). The model outputs ~400 patch embeddings per page, each a 128-dimensional vector. We compute spatial bounding boxes from the model’s patch grid dimensions and store everything (embeddings, bounding boxes, document ID, page number, model version) in pgvector.
The storage schema uses a composite uniqueness constraint on (document_id, page_number, patch_index, model_version), which lets us store embeddings from multiple model versions side by side for A/B evaluation.
Querying: Patches to Pages to Answers
The query pipeline has three stages.
Stage 1: Query Embedding
The query string is tokenized and embedded by ColPali’s text encoder, producing per-token embeddings that are mean-pooled into a single 128-dimensional vector:
\mathbf{q} = \frac{1}{|\mathcal{T}|} \sum_{t \in \mathcal{T}} \mathbf{e}_twhere 𝒯 is the set of non-padding tokens. Mean pooling is a simplification. The original ColBERT formulation uses late-interaction scoring (MaxSim across all query tokens and all document patches), which is more expressive but requires retaining and comparing full token sequences at search time. In a pgvector-based architecture where search happens inside the database, mean pooling trades some retrieval precision for architectural simplicity and query-time efficiency.
Stage 2: Patch Retrieval and Page Aggregation
The pooled query vector is used for ANN search over the HNSW index. The top K patches (default 40) are returned with cosine similarity scores. But raw patch scores don’t directly tell us which pages are most relevant. That requires aggregation.
Retrieved patches are grouped by (document_id, page_number). For each page p, we take the top M patches (default 5) by score and compute a rank-weighted aggregate:
S(p) = \sum_{j=1}^{\min(M,\, |H_p|)} \frac{s_{\pi_j}}{j + 1}where H_p is the set of retrieved patches on page p and π sorts them by descending score. The reciprocal-rank weighting is important: it ensures that a page with several consistently relevant patches scores higher than a page with one high outlier. Without it, a single noisy high-scoring patch can dominate.
Pages are ranked by S(p) and filtered through a per-document diversity constraint: at most 2 pages from any single document. This prevents a long, broadly relevant document from monopolizing results.
Stage 3: Answer Generation
When requested, the system renders the top-ranked pages as images and sends them alongside the original query to an LLM (Azure OpenAI or Google Gemini). The LLM receives page images, not extracted text, so the visual fidelity of the source material is preserved through the entire pipeline.
The Storage Problem
Here is the practical scaling concern with patch-level embeddings.
At N_p ≈ 400 patches per page × 128 dimensions × 4 bytes per float, each page requires roughly 200 KB of embedding storage. A 100-page document produces ~20 MB. A corpus of 10,000 documents at 50 pages average amounts to roughly 100 GB of embeddings alone, excluding HNSW index overhead. And HNSW search latency degrades as the total vector count grows.
The granularity that makes retrieval good — patch-level embeddings — is the same thing that makes storage expensive. This is the central tension in ColPali-style systems.
Light-ColPali: Reducing Storage Through Token Merging
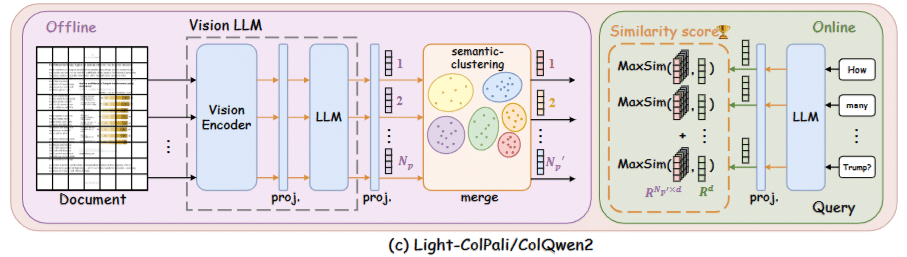
Light-ColPali, introduced by Jha et al. [4], addresses this directly. The observation is simple: many patches on a page are semantically redundant. Background regions, contiguous text blocks, and adjacent whitespace all produce highly similar embeddings. If we merge similar patches after the model generates them, we store fewer vectors while preserving the information that matters for retrieval.
The Merging Procedure
Given a page’s N_p patch embeddings, the procedure follows four steps.
Distance computation. Pairwise cosine similarities are computed and transformed to distances:
d_{ij} = 1 - \frac{\text{sim}_{\cos}(\mathbf{e}_i, \mathbf{e}_j) + 1}{2}This maps cosine similarity [−1, 1] to distance [0, 1].
Hierarchical clustering. Average-linkage agglomerative clustering (via SciPy’s linkage and fcluster) is applied to the condensed distance matrix, producing a linkage tree that is then cut to yield N_p’ clusters:
N_p' = \max\left(N_{\min},\; \left\lfloor \frac{N_p}{f} \right\rfloor\right)where f is the merge factor and N_min is a floor (default 32) to prevent over-merging on pages with few patches.
Mean aggregation. Each cluster is represented by the mean of its member embeddings, following the approach described in the Light-ColPali paper:
\hat{\mathbf{e}}_k = \frac{1}{|C_k|} \sum_{i \in C_k} \mathbf{e}_iSpatial bounding boxes. Each original patch has a known position on the page. When patches are merged into clusters, we need a bounding box for the cluster. A naive union of all member bounding boxes produces excessively large regions when semantically similar patches are spatially scattered (like repeated boilerplate text in a header and footer). We use a density-based approach instead: compute the spatial median of member patch centers, discard patches beyond the 75th percentile of distance from that median, and take the bounding box of the remaining core patches. For clusters with 6 or fewer members, the plain union is used since outlier filtering is unreliable with very small samples.
How Much Does It Help?
Jha et al. [4] report the following on standard document retrieval benchmarks:
| Merge Factor | Patches Retained | Memory | NDCG Retained |
|---|---|---|---|
| 9× | ~11.8% | ~11.8% | ~98.2% |
| 25× | ~4.0% | ~3.0% | ~96.3% |
| 49× | ~2.0% | ~1.8% | ~94.6% |
A merge factor of 9 is the practical sweet spot: embedding storage per page drops from ~200 KB to ~22 KB, the HNSW index shrinks proportionally, and retrieval quality barely moves.
Integration
In our implementation, Light-ColPali is a configurable post-processing step toggled by a single environment variable (LIGHT_MERGE_ENABLED=true). When enabled, the embedding provider routes page embeddings through a LightMerger that clusters and aggregates before storage. The query pipeline requires no modification. It performs the same vector search and page aggregation over the smaller embedding set. Token merging is purely an ingestion-time optimization, invisible to downstream consumers.
Engineering Tradeoffs
A few decisions are worth calling out explicitly.
Vision RAG is not always the right choice. For purely textual documents like novels, contracts, and plain-text articles, text-based RAG with mature chunking strategies is simpler, cheaper, and often just as effective. Vision RAG shines when documents contain complex layouts, tables, charts, diagrams, or any content where spatial structure carries semantic meaning. In practice, most enterprise document corpora fall into this category, but it is worth evaluating per use case.
Mean pooling is a deliberate compromise. ColBERT’s MaxSim scoring compares all query tokens against all document patches and is more expressive. But in a pgvector architecture, that would require either multiple ANN queries per search or a custom scoring layer outside the database. Mean pooling sacrifices some precision for operational simplicity. A plausible middle ground would be to use mean pooling for the initial retrieval and apply MaxSim as a reranking step over the top results, but we have not implemented this.
PostgreSQL as task queue. Using a dedicated message broker like Celery or RabbitMQ would add another infrastructure dependency. The PostgreSQL-based job queue is simpler to operate and gives us transactional consistency between job state and embedding storage. The lease mechanism with SELECT ... FOR UPDATE SKIP LOCKED and a time-limited lease is atomic and handles worker crashes gracefully. If a worker dies, the lease simply expires and another worker picks up the job.
Per-document diversity is a simple heuristic. Capping results at 2 pages per document prevents a long document from dominating results, but more sophisticated approaches like Maximal Marginal Relevance (MMR) [7] could improve diversity further. For our use cases, the simple cap has been effective.
Conclusion
ColPali [1] and Light-ColPali [4] provide the core techniques. What we built is the production plumbing around them: a resilient ingestion pipeline with failure recovery and deduplication, a two-stage retrieval pipeline that bridges patch-level granularity with page-level result presentation, and the infrastructure choices (PostgreSQL as unified store, HNSW indexing, lease-based job coordination) that make the system deployable and operable.
The key insight from this work is that vision-based document retrieval is practical at scale. ColPali’s patch-level embeddings solve the information loss problem inherent in text extraction, and Light-ColPali’s token merging brings the storage costs back to a manageable range. At a 9× merge factor, we retain 98.2% of retrieval quality while reducing storage by nearly an order of magnitude.
For documents where visual structure matters, which in enterprise and research settings is most of them, this approach is worth serious consideration.
References
[1] M. Faysse, H. Fernandez, P. Music, et al., “ColPali: Efficient Document Retrieval with Vision Language Models,” arXiv preprint arXiv:2407.01449, 2024.
[2] O. Khattab and M. Zaharia, “ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT,” Proceedings of SIGIR, 2020.
[3] P. Wang, S. Bai, et al., “Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution,” arXiv preprint arXiv:2409.12191, 2024.
[4] R. Jha, et al., “Light-ColPali: Efficient Document Retrieval with Token Merging,” arXiv preprint arXiv:2506.04997, 2025.
[5] P. Lewis, E. Perez, A. Piktus, et al., “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,” NeurIPS, 2020.
[6] L. Wang, N. Yang, X. Huang, et al., “Text Embeddings by Weakly-Supervised Contrastive Pre-training,” arXiv preprint arXiv:2212.03533, 2022.
[7] J. Carbonell and J. Goldstein, “The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries,” SIGIR, 1998.